Documentation Index
Fetch the complete documentation index at: https://docs.vidol.chat/llms.txt
Use this file to discover all available pages before exploring further.
Using Groq in LobeVidol
 Groq’s LPU inference engine has excelled in the latest independent large language model (LLM) benchmark tests, redefining the standards for AI solutions with its astonishing speed and efficiency. With the integration of LobeVidol and Groq Cloud, you can now easily leverage Groq’s technology to accelerate the performance of large language models in LobeVidol.
Groq’s LPU inference engine has excelled in the latest independent large language model (LLM) benchmark tests, redefining the standards for AI solutions with its astonishing speed and efficiency. With the integration of LobeVidol and Groq Cloud, you can now easily leverage Groq’s technology to accelerate the performance of large language models in LobeVidol.
The Groq LPU inference engine has consistently achieved a speed of 300 tokens per second in internal benchmark tests, confirmed by benchmarks from ArtificialAnalysis.ai, showing that Groq outperforms other providers in throughput (241 tokens per second) and total time to receive 100 output tokens (0.8 seconds).
Step 1: Obtain a GroqCloud API Key
First, you need to obtain an API Key from the GroqCloud Console.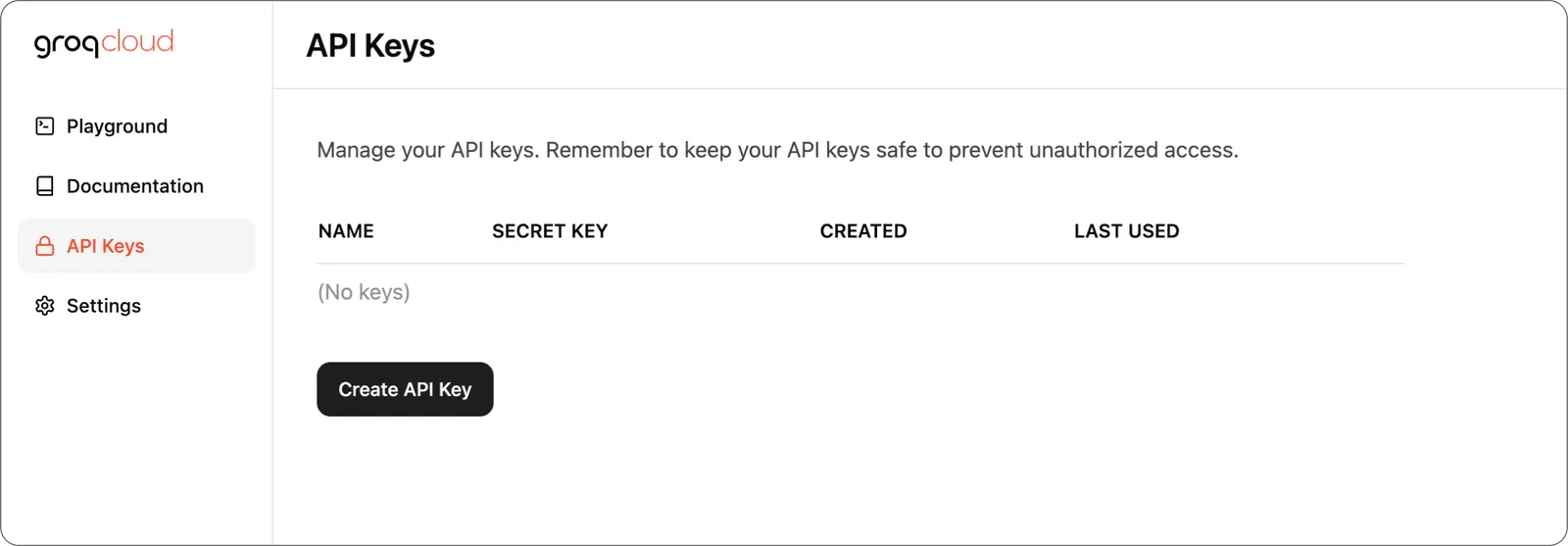 Create an API Key in the
Create an API Key in the API Keys menu of the console.
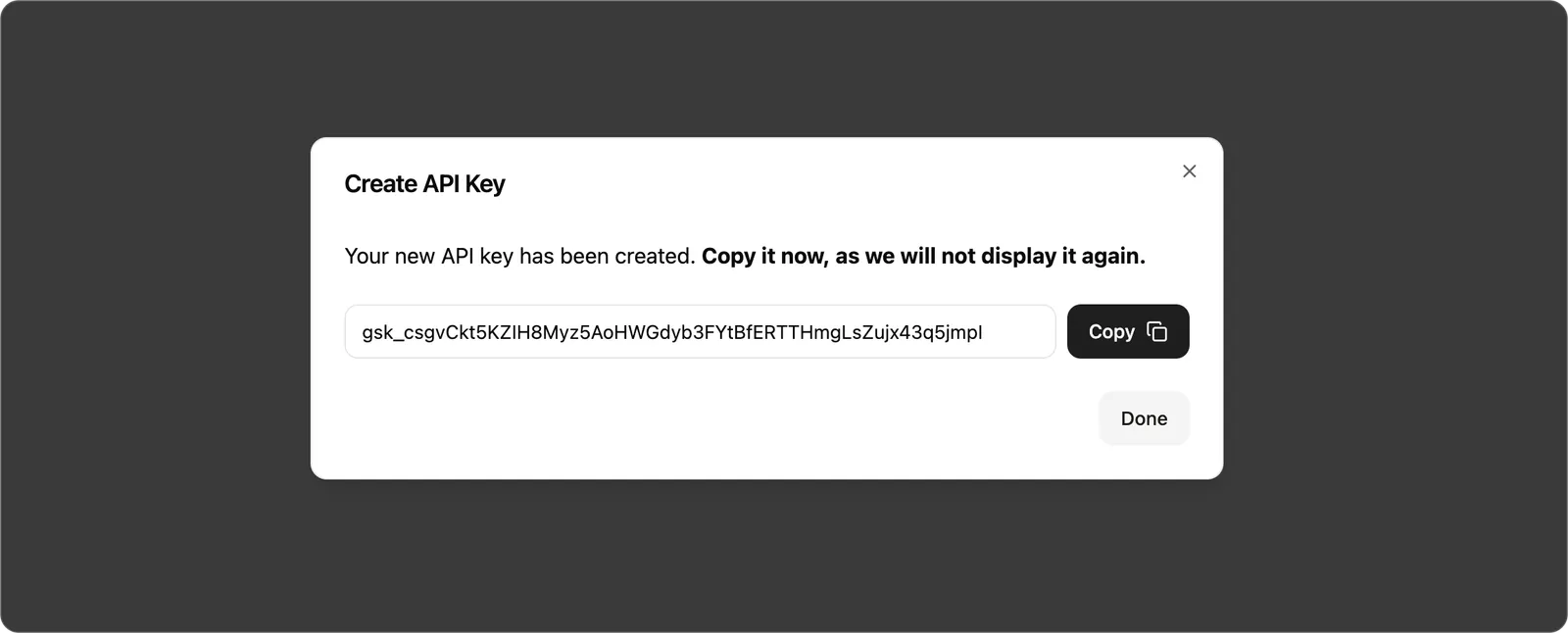
Step 2: Configure Groq in LobeVidol
You can find the configuration options for Groq inSettings -> Language Models, where you can enter the API Key you just obtained.
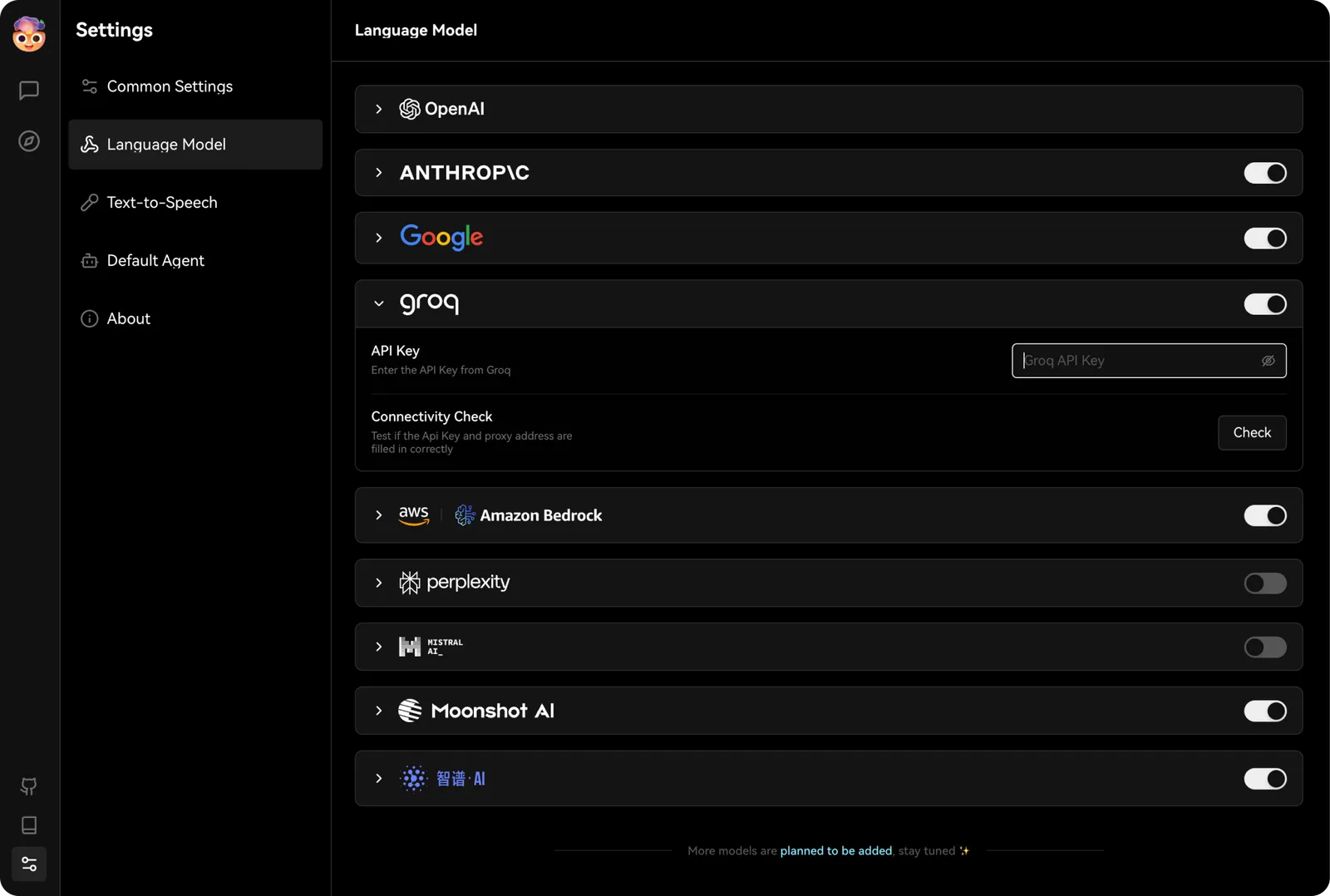 Next, select a Groq-supported model in the assistant’s model options, and you can experience the powerful performance of Groq in LobeVidol.
Next, select a Groq-supported model in the assistant’s model options, and you can experience the powerful performance of Groq in LobeVidol.