大規模言語モデルはキャラクターの「脳」であり、キャラクターの具体的な表現は異なるモデルや関連するパラメータの設定に依存します。設定方法がわからない場合は、デフォルトの設定を維持してください:Documentation Index
Fetch the complete documentation index at: https://docs.vidol.chat/llms.txt
Use this file to discover all available pages before exploring further.
モデル model
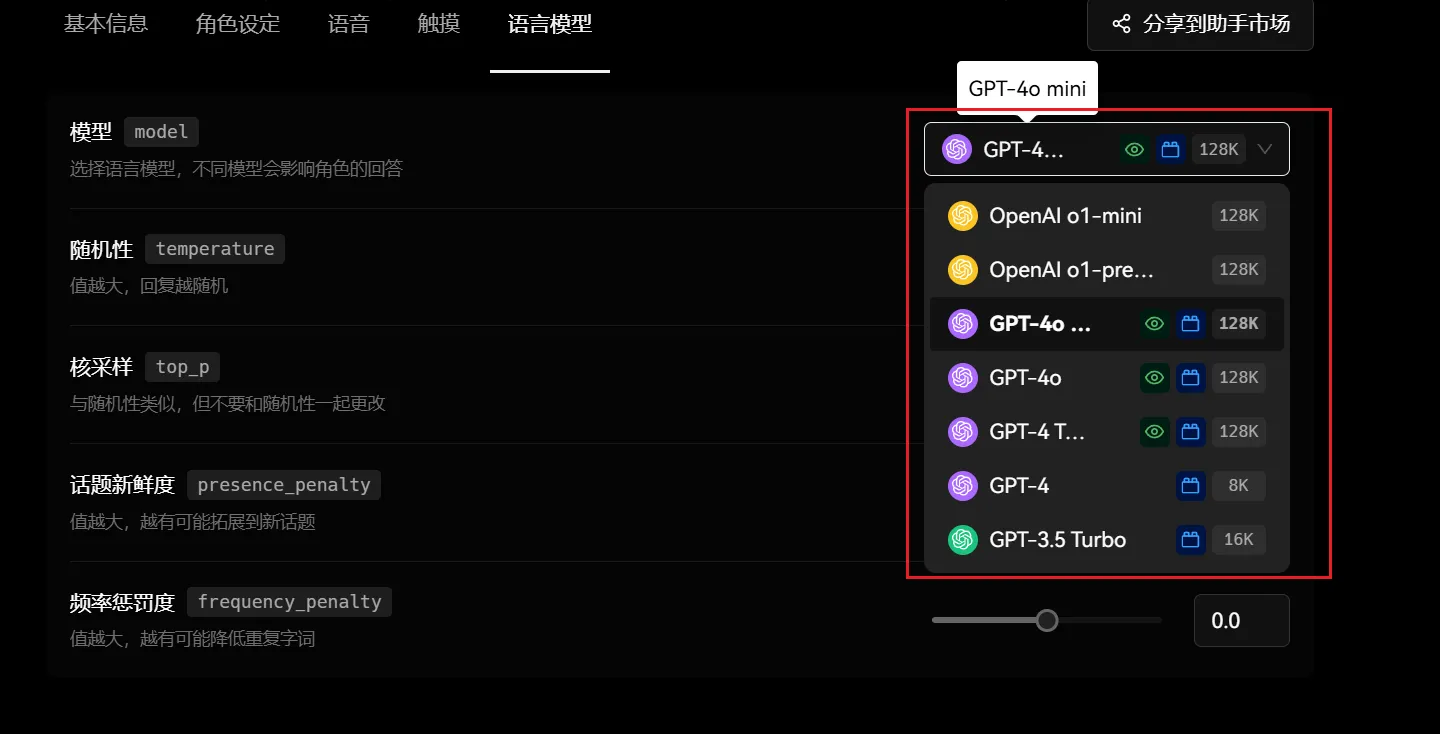
モデルは異なる大規模モデルサービスプロバイダーとその具体的なモデルパラメータを選択することを意味します。異なる言語モデルを選択することで、キャラクターの応答に大きな影響を与えます。異なるモデルは、言語理解、生成能力、正確性、スタイルなどの面で差異がある可能性があります。例えば、特定の分野の問題を処理するのが得意なモデルもあれば、創造的な回答を生成するのが得意なモデルもあります。
現在、LobeVidolはOpenAI APIの呼び出しをサポートしています:
ランダム性 temperature
このパラメータは、応答のランダム性の程度を制御します。値が大きいほど、モデルは応答を生成する際によりランダムになり、より異常で創造的な回答を提供する可能性がありますが、正確性が低下する可能性もあります。逆に、値が小さいと、モデルの応答はより確実で保守的になり、一般的で信頼性の高い答えを提供する傾向があります。

核サンプリング top_p
ランダム性と似ており、モデルが生成する応答の多様性と不確実性にも影響を与えます。ただし、ランダム性のパラメータと一緒に変更しないでください。両者の作用には一定の重複があり、同時に調整すると予測不可能な結果を招く可能性があります。

トピックの新鮮さ presence_penalty
このパラメータは、モデルが質問に答える際に新しいトピックに広がる傾向を制御します。値が大きいほど、モデルは新しいトピックや視点を導入する可能性が高くなり、応答がより豊かで多様化します。しかし、値が大きすぎると、応答が質問の核心から逸れる可能性があります。
