Documentation Index
Fetch the complete documentation index at: https://docs.vidol.chat/llms.txt
Use this file to discover all available pages before exploring further.
 Ollama est un cadre puissant pour exécuter localement des modèles de langage de grande taille (LLM), prenant en charge divers modèles de langage, y compris Llama 2, Mistral, etc. Désormais, LobeVidol prend en charge l’intégration avec Ollama, ce qui signifie que vous pouvez facilement utiliser les modèles de langage fournis par Ollama dans LobeVidol pour améliorer vos applications.
Ce document vous guidera sur la façon d’utiliser Ollama dans LobeVidol :
Ollama est un cadre puissant pour exécuter localement des modèles de langage de grande taille (LLM), prenant en charge divers modèles de langage, y compris Llama 2, Mistral, etc. Désormais, LobeVidol prend en charge l’intégration avec Ollama, ce qui signifie que vous pouvez facilement utiliser les modèles de langage fournis par Ollama dans LobeVidol pour améliorer vos applications.
Ce document vous guidera sur la façon d’utiliser Ollama dans LobeVidol :
Utiliser Ollama sur macOS
Installer Ollama localement
Téléchargez Ollama pour macOS et décompressez-le, puis installez-le.
Configurer Ollama pour autoriser l'accès cross-origin
En raison de la configuration par défaut d’Ollama, il est réglé pour un accès local uniquement au démarrage, donc l’accès cross-origin et l’écoute des ports nécessitent des réglages supplémentaires des variables d’environnement
OLLAMA_ORIGINS. Utilisez launchctl pour définir la variable d’environnement :
Utiliser Ollama sur Windows
Téléchargez Ollama pour Windows et installez-le.
En raison de la configuration par défaut d’Ollama, il est réglé pour un accès local uniquement au démarrage, donc l’accès cross-origin et l’écoute des ports nécessitent des réglages supplémentaires des variables d’environnement
OLLAMA_ORIGINS.OLLAMA_ORIGINS pour votre compte utilisateur, avec la valeur *.OK/Appliquer pour enregistrer, puis redémarrez le système.Ollama.Utiliser Ollama sur Linux
Ou, vous pouvez également consulter le guide d’installation manuelle pour Linux.
En raison de la configuration par défaut d’Ollama, il est réglé pour un accès local uniquement au démarrage, donc l’accès cross-origin et l’écoute des ports nécessitent des réglages supplémentaires des variables d’environnement
OLLAMA_ORIGINS. Si Ollama fonctionne en tant que service systemd, vous devez utiliser systemctl pour définir la variable d’environnement :Déployer Ollama avec Docker
Si vous préférez utiliser Docker, Ollama propose également une image Docker officielle que vous pouvez tirer avec la commande suivante :
En raison de la configuration par défaut d’Ollama, il est réglé pour un accès local uniquement au démarrage, donc l’accès cross-origin et l’écoute des ports nécessitent des réglages supplémentaires des variables d’environnement
OLLAMA_ORIGINS.Si Ollama fonctionne en tant que conteneur Docker, vous pouvez ajouter la variable d’environnement à la commande
docker run.docker run -d --gpus=all -v ollama:/root/.ollama -e OLLAMA_ORIGINS="*" -p 11434:11434 --name ollama ollama/ollama
Installer des modèles Ollama
Ollama prend en charge divers modèles, vous pouvez consulter la liste des modèles disponibles dans Ollama Library et choisir le modèle qui vous convient.Installation dans LobeVidol
Dans LobeVidol, nous avons par défaut activé certains modèles de langage courants, tels que llama3, Gemma, Mistral, etc. Lorsque vous sélectionnez un modèle pour dialoguer, nous vous informerons que vous devez télécharger ce modèle.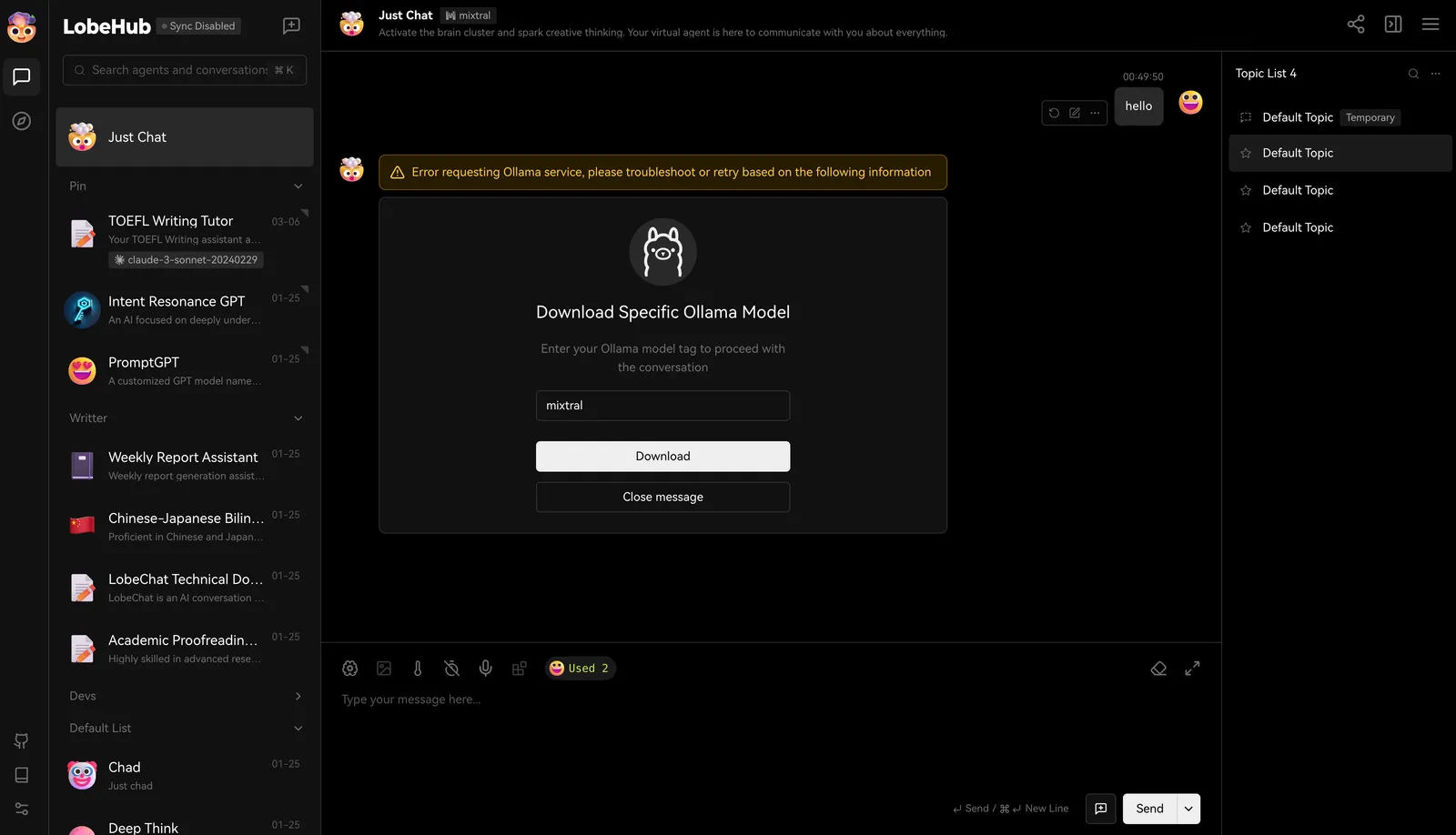 Une fois le téléchargement terminé, vous pouvez commencer à dialoguer.
Une fois le téléchargement terminé, vous pouvez commencer à dialoguer.
Utiliser Ollama pour tirer des modèles localement
Bien sûr, vous pouvez également installer des modèles en exécutant la commande suivante dans le terminal, en prenant llama3 comme exemple :Configuration personnalisée
Vous pouvez trouver les options de configuration d’Ollama dansParamètres -> Modèle de langage, où vous pouvez configurer le proxy, le nom du modèle, etc.
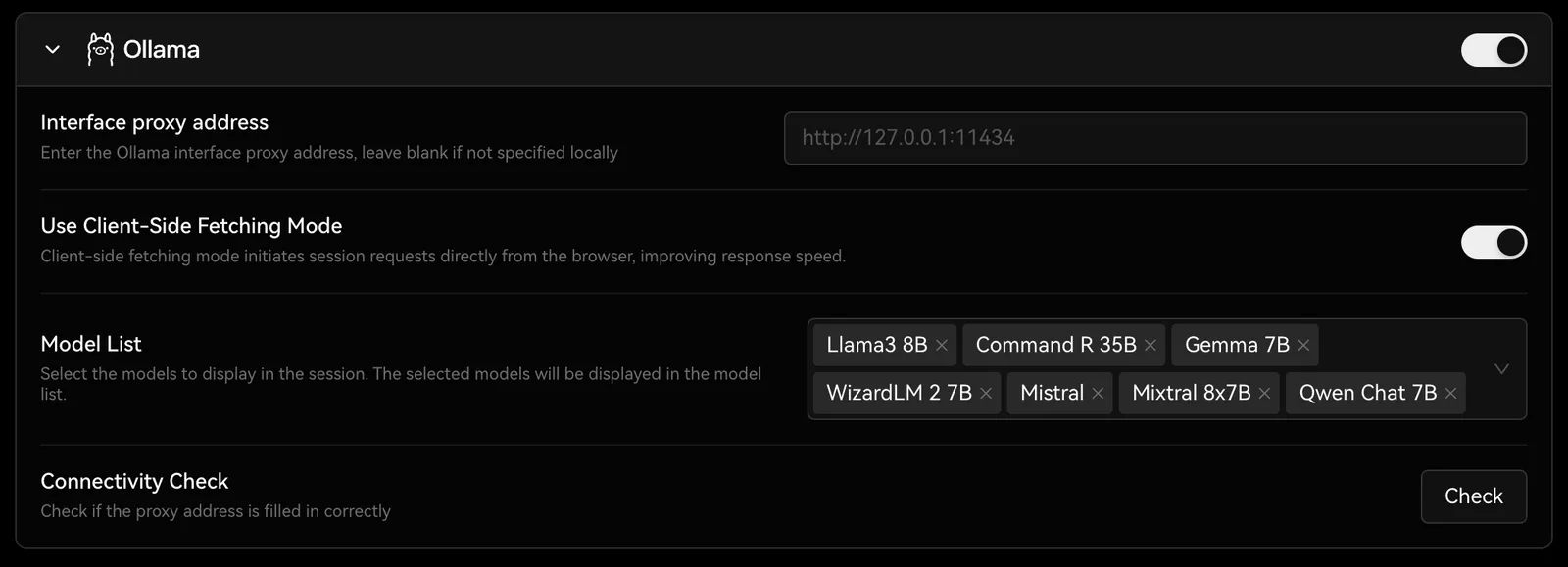
Vous pouvez consulter Intégration avec Ollama pour en savoir plus sur le déploiement de LobeVidol afin de répondre aux besoins d’intégration avec Ollama.