Documentation Index
Fetch the complete documentation index at: https://docs.vidol.chat/llms.txt
Use this file to discover all available pages before exploring further.
Utiliser Groq dans LobeVidol
 Le moteur d’inférence LPU de Groq a excellé dans les derniers benchmarks indépendants des grands modèles de langage (LLM), redéfinissant les normes des solutions d’IA avec sa vitesse et son efficacité impressionnantes. Grâce à l’intégration de LobeVidol avec Groq Cloud, vous pouvez désormais tirer parti de la technologie de Groq pour accélérer l’exécution des grands modèles de langage dans LobeVidol.
Le moteur d’inférence LPU de Groq a excellé dans les derniers benchmarks indépendants des grands modèles de langage (LLM), redéfinissant les normes des solutions d’IA avec sa vitesse et son efficacité impressionnantes. Grâce à l’intégration de LobeVidol avec Groq Cloud, vous pouvez désormais tirer parti de la technologie de Groq pour accélérer l’exécution des grands modèles de langage dans LobeVidol.
Le moteur d’inférence LPU de Groq a atteint une vitesse de 300 tokens par seconde lors de tests internes, et selon les benchmarks d’ArtificialAnalysis.ai, Groq surpasse les autres fournisseurs en termes de débit (241 tokens par seconde) et de temps total pour recevoir 100 tokens de sortie (0,8 seconde).
Étape 1 : Obtenir une clé API GroqCloud
Tout d’abord, vous devez obtenir une clé API dans le GroqCloud Console.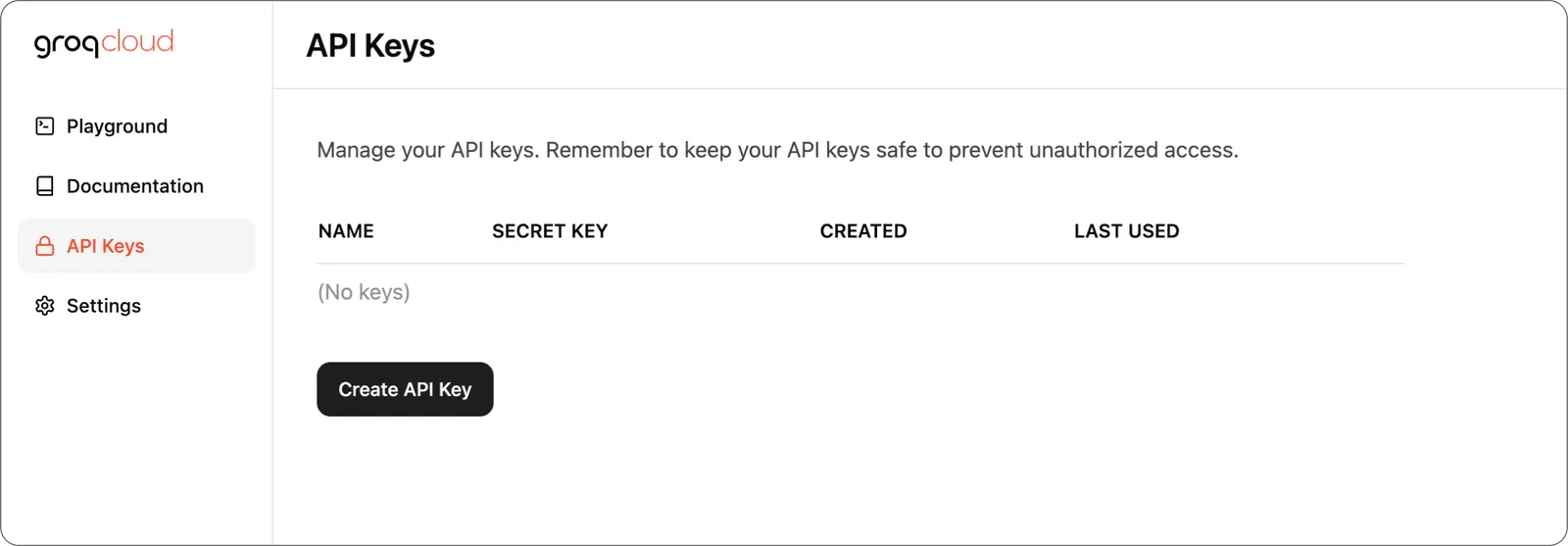 Créez une clé API dans le menu
Créez une clé API dans le menu Clés API de la console.
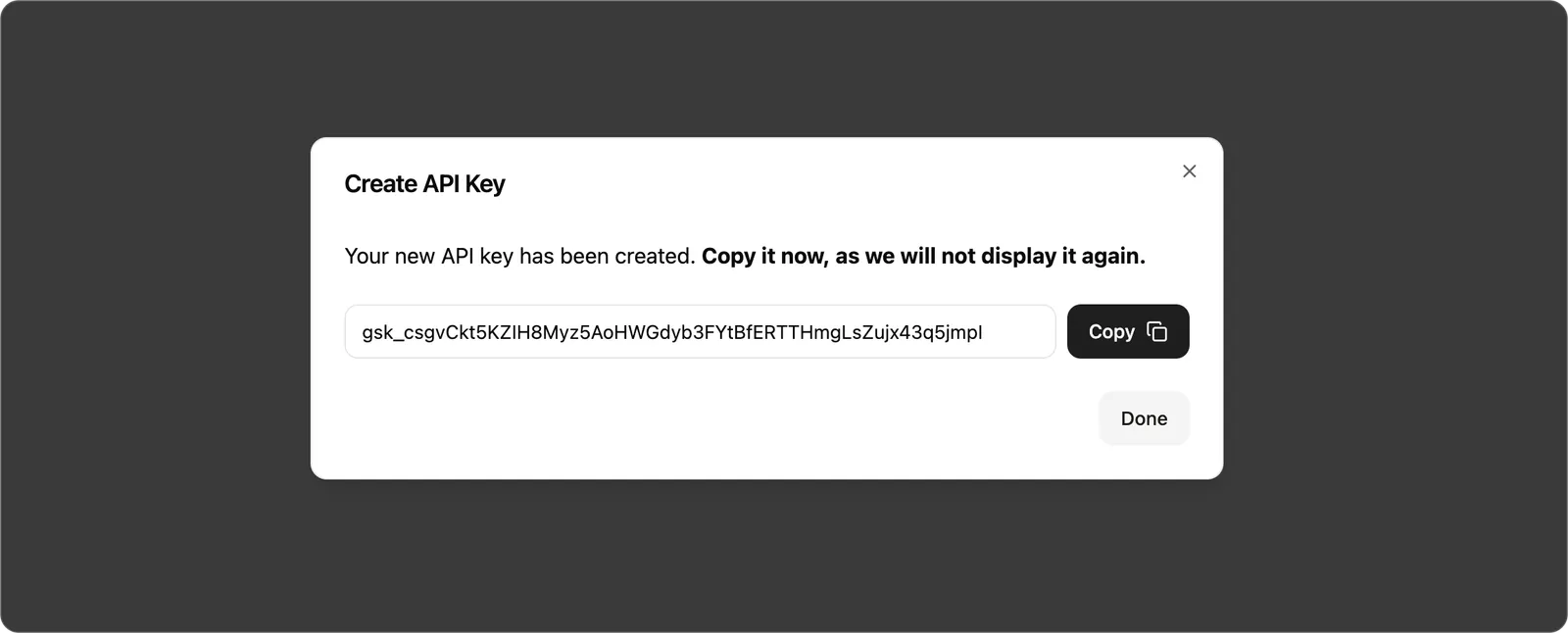
Étape 2 : Configurer Groq dans LobeVidol
Vous pouvez trouver les options de configuration de Groq dansParamètres -> Modèles de langage, où vous pourrez entrer la clé API que vous venez d’obtenir.
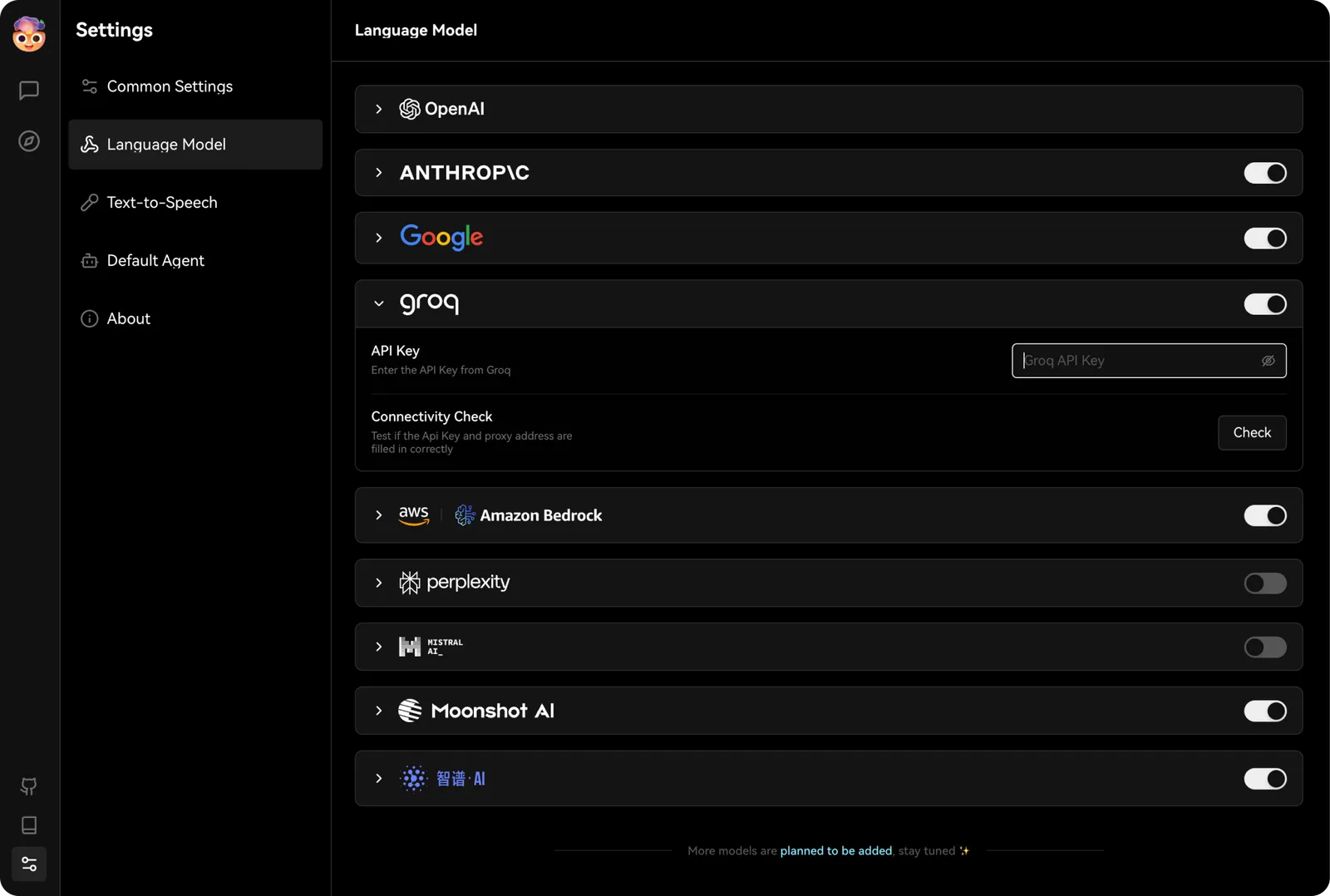 Ensuite, dans les options de modèle de l’assistant, sélectionnez un modèle pris en charge par Groq pour commencer à profiter de la puissance de Groq dans LobeVidol.
Ensuite, dans les options de modèle de l’assistant, sélectionnez un modèle pris en charge par Groq pour commencer à profiter de la puissance de Groq dans LobeVidol.