Documentation Index
Fetch the complete documentation index at: https://docs.vidol.chat/llms.txt
Use this file to discover all available pages before exploring further.
 Ollamaは、Llama 2やMistralなど、さまざまな言語モデルをサポートする強力なローカル実行の大規模言語モデル(LLM)フレームワークです。現在、LobeVidolはOllamaとの統合をサポートしており、LobeVidol内でOllamaが提供する言語モデルを簡単に使用してアプリケーションを強化できます。
このドキュメントでは、LobeVidolでOllamaを使用する方法を説明します:
Ollamaは、Llama 2やMistralなど、さまざまな言語モデルをサポートする強力なローカル実行の大規模言語モデル(LLM)フレームワークです。現在、LobeVidolはOllamaとの統合をサポートしており、LobeVidol内でOllamaが提供する言語モデルを簡単に使用してアプリケーションを強化できます。
このドキュメントでは、LobeVidolでOllamaを使用する方法を説明します:
macOSでOllamaを使用する
Ollamaをローカルにインストール
macOS用Ollamaをダウンロードし、解凍してインストールします。
Ollamaのクロスオリジンアクセスを許可する設定
Ollamaのデフォルト設定では、起動時にローカルアクセスのみが設定されているため、クロスオリジンアクセスとポートリスニングには追加の環境変数設定
OLLAMA_ORIGINSが必要です。launchctlを使用して環境変数を設定します:WindowsでOllamaを使用する
Windows用Ollamaをダウンロードし、インストールします。
OLLAMA_ORIGINSを編集または新規作成し、値を*に設定します。OK/適用をクリックして保存し、システムを再起動します。Ollamaを再実行します。LinuxでOllamaを使用する
または、Linux手動インストールガイドを参照することもできます。
Ollamaのデフォルト設定では、起動時にローカルアクセスのみが設定されているため、クロスオリジンアクセスとポートリスニングには追加の環境変数設定
OLLAMA_ORIGINSが必要です。Ollamaがsystemdサービスとして実行されている場合、systemctlを使用して環境変数を設定する必要があります:Dockerを使用してOllamaをデプロイする
docker run -d --gpus=all -v ollama:/root/.ollama -e OLLAMA_ORIGINS="*" -p 11434:11434 --name ollama ollama/ollama
Ollamaモデルのインストール
Ollamaはさまざまなモデルをサポートしており、Ollamaライブラリで利用可能なモデルのリストを確認し、ニーズに合ったモデルを選択できます。LobeVidolでのインストール
LobeVidolでは、llama3、Gemma、Mistralなどの一般的な大規模言語モデルがデフォルトで有効になっています。モデルを選択して対話を開始すると、そのモデルをダウンロードする必要があることを通知します。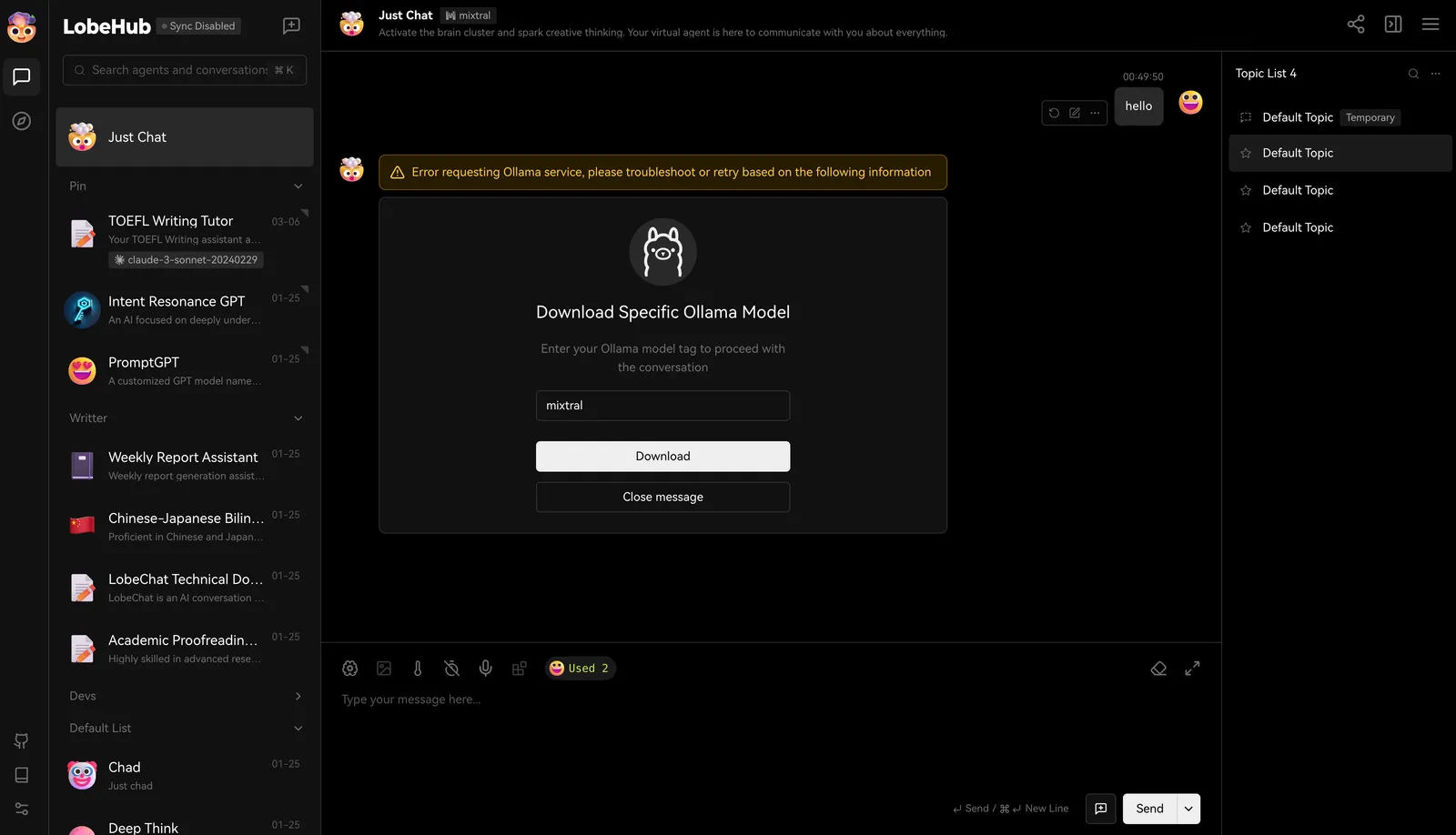 ダウンロードが完了したら、対話を開始できます。
ダウンロードが完了したら、対話を開始できます。
Ollamaを使用してモデルをローカルにプルする
もちろん、ターミナルで以下のコマンドを実行してモデルをインストールすることもできます。llama3の例:カスタム設定
設定 -> 言語モデルでOllamaの設定オプションを見つけることができ、ここでOllamaのプロキシ、モデル名などを設定できます。
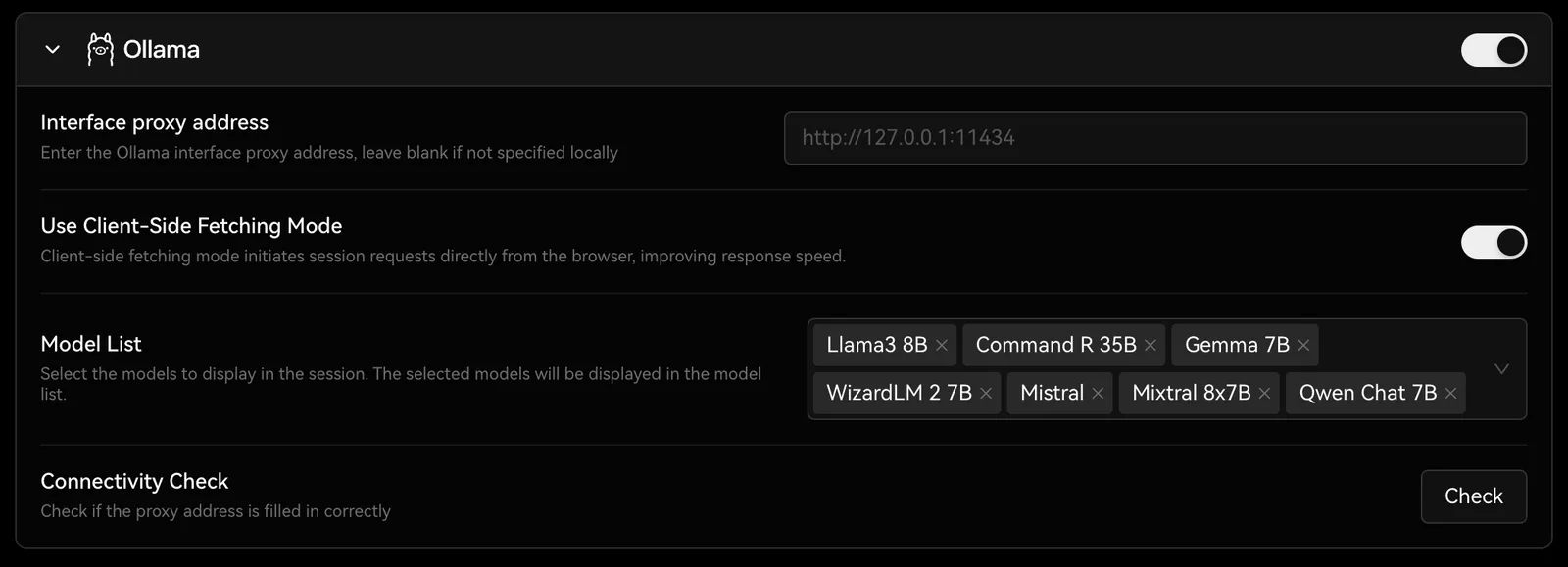
Ollamaとの統合にアクセスして、Ollamaとの統合要件を満たすためにLobeVidolをデプロイする方法を学ぶことができます。