Le modèle de langue est le cerveau du personnage, et l’expression concrète du personnage dépend également des différents modèles et des paramètres associés. Si vous n’êtes pas sûr de la configuration, il est préférable de conserver les paramètres par défaut :Documentation Index
Fetch the complete documentation index at: https://docs.vidol.chat/llms.txt
Use this file to discover all available pages before exploring further.
Modèle model
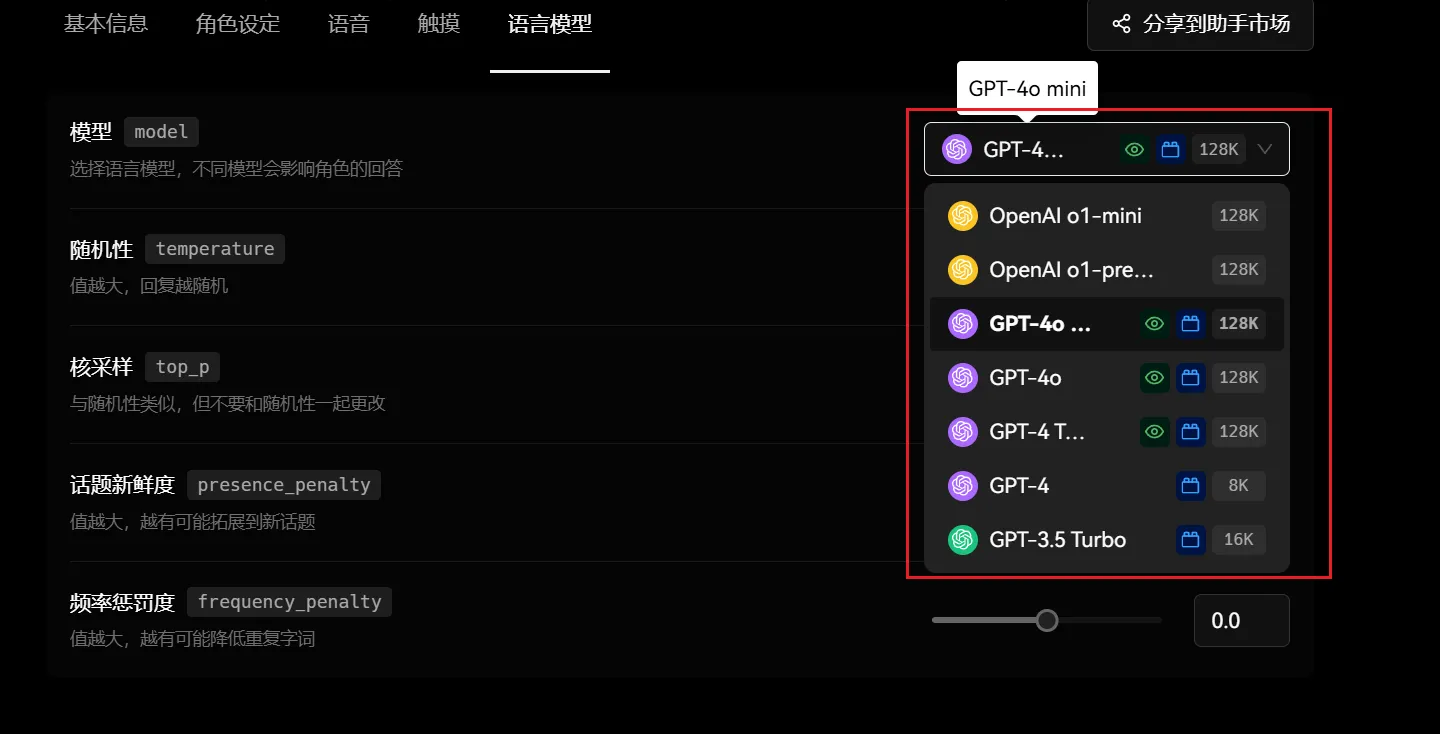
Le modèle consiste à choisir différents fournisseurs de services de modèles de grande taille et leurs paramètres spécifiques. Le choix d’un modèle de langue différent peut avoir un impact significatif sur les réponses du personnage. Les différents modèles peuvent varier en termes de compréhension linguistique, de capacité de génération, de précision, de style, etc. Par exemple, certains modèles peuvent être plus compétents pour traiter des questions dans des domaines spécifiques, tandis que d’autres peuvent exceller dans la génération de réponses créatives.
Actuellement, LobeVidol prend en charge les appels à l’API OpenAI :
Aléatoire temperature
Ce paramètre contrôle le degré de randomisation des réponses. Lorsque la valeur est élevée, le modèle génère des réponses plus aléatoires, ce qui peut donner lieu à des réponses plus inhabituelles et créatives, mais cela peut également réduire la précision des réponses. En revanche, lorsque la valeur est faible, les réponses du modèle sont plus déterminées et conservatrices, tendant à fournir des réponses plus courantes et fiables.

Échantillonnage Nucleus top_p
Semblable à l’aléatoire, ce paramètre influence également la diversité et l’incertitude des réponses générées par le modèle. Cependant, il ne faut pas modifier ce paramètre en même temps que le paramètre d’aléatoire, car leurs effets se chevauchent, et les ajustements simultanés peuvent entraîner des résultats imprévisibles.

Fraîcheur des sujets presence_penalty
Ce paramètre contrôle la tendance du modèle à aborder de nouveaux sujets lors de la réponse à des questions. Lorsque la valeur est élevée, le modèle est plus susceptible d’introduire de nouveaux sujets ou points de vue, rendant les réponses plus riches et diversifiées. Cependant, si la valeur est trop élevée, cela peut entraîner un éloignement du cœur de la question.
